- Implementation
The Art and Science Behind a Robust, Scalable Salesforce Case Categorization Model
Luke Kotowski, Senior Solution Architect here at Catalyst, discusses the organizational impact of a robust case categorization model.
Catalyst is a 3-Time Salesforce Partner Innovation Award Winner. Learn More.
Luke Kotowski, Senior Solution Architect here at Catalyst, discusses the organizational impact of a robust case categorization model.
This blog post was written by Luke Kotowski, Senior Salesforce Solution Architect here at Catalyst. Luke discusses how to implement an impactful case categorization model that accurately describes records housed within a Salesforce CRM. He underscores the importance of such a model as it can heighten employee morale, minimize manual labor, improve data quality, and lead to time savings that translate into higher quality customer service.
Any Customer Relationship Management (CRM) application worth having should illuminate trends in your data that inform how to improve your business processes. After all, why collect reams of data in a CRM if not to help your organization do better work? The categorization model used to describe your data is paramount–it must equip end users with digestible, clear verbiage that describe their day-to-day responsibilities accurately.
Designing a categorization model requires deliberate and careful thought— you need to make sure the available options are varied enough that they can describe all possible scenarios, but not so many that the model becomes challenging to use. Identifying this point of diminishing returns is key to striking the correct balance.
Below, we detail how Catalyst navigated these considerations with Salesforce Service Cloud as we stood up a categorization model for a customer service organization within a major international airport in the Pacific Northwest.
We’ve found success by infusing new life into traditional picklists by soliciting end user feedback on the values available in reference records, as well as tapping into artificial intelligence to make the categorization process easier.

Yikes, look at all these picklists.
The standard CRM categorization system is the picklist — a drop-down list of pre-selected values that allow users to assign data to a defined category. Picklists are helpful because they standardize data entry and improve data quality while supplying guardrails against inconsistent formatting.
While picklists are integral to data collection, the experience of using them is decidedly uninspiring.
Nothing makes an end user decide to take an early lunch like seeing a wall of required drop-down fields staring back at them from their screen. It’s time-consuming and feels antiquated, not to mention that the process of filling out a series of picklists, arranged in a pre-determined order, does not accommodate how people naturally want to discuss the phenomena around them.
Think about it. If you were to sit two people down and ask them to describe a customer interaction, the first might begin by discussing the overarching theme of the interaction, while the second might remark on the location the customer visited to prompt the outreach.
If we can create a model that allows our users to describe their work on their own terms, then we can create an intuitive user experience that does not compromise the value or accuracy of categorization.
While we want to make sure to offer users the necessary latitude to categorize their work accurately and efficiently, it’s equally important to make sure that the organization uses a consistent language that scales with the enterprise. For our client in the Pacific Northwest, the answer to creating this shared language lay in using reference data.
We are reference data evangelists here at Catalyst. Correctly implemented, reference data has a broad range of uses that can be used to control many different types of system behavior without actually changing any Salesforce configuration. For example, reference data records might inform the physical locations in an airport that a representative can associate with a Case, as they do for our client in the PNW.
We always advise that a select group of business superusers – not an administrator – create and maintain reference data records. That way, the solution empowers users to create the language they themselves use to describe their work, while also lessening the burden of maintenance on the administrator.
We also recommend that there be a proposal process for new reference data values. Even though most users should not be able to insert reference records on their own, it’s imperative to keep the entire user base engaged in the work of designing the model. Allowing them to propose new reference records can help ensure that their ideas are heard while ensuring that they are properly vetted out.
We saw this democratic method at play with our client as we implemented their solution; their team brainstormed values to describe cases related to COVID-19 and selected the options viewed most favorably by most stakeholders. As we move into 2021, we’re confident their users will be able to leverage the reference data framework we created to accommodate the ever-broadening topics of conversation that customers reach out about.
Let’s say our picklists – and the values available within them – are agreed upon. There’s one more step to take before we can get to work serving customers: machine learning.
Applying standards consistently across cases can be difficult, and the variance in data quality will scale with the size of a service organization, as enforcing categorization standards becomes difficult due to the subjectivity that each newly onboarded resource introduces.
To minimize the possibility of human error as part of our implementation, we used Salesforce’s Einstein Case Classification (ECC) product. ECC uses the power of Salesforce’s artificial intelligence technology to predict case field values based on historical data.
By comparing the subject and description values of past cases against their user-selected field values, Einstein develops a sense of the commonalities between cases with the same values. ECC then uses this information to make predictions as to what field values should be on incoming cases without introducing any additional subjectivity into the equation, saving users time and allowing for a consistent application of your categorization model.
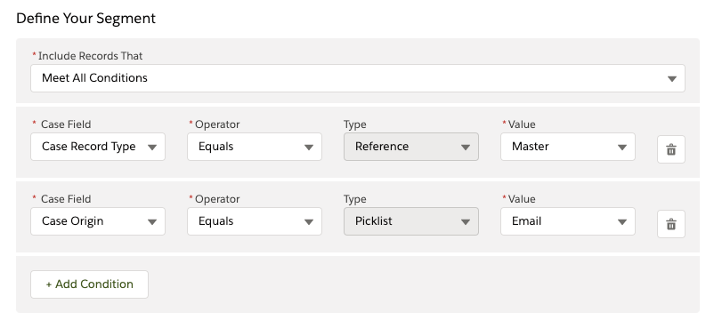
Setting up an ECC model is straightforward—there’s no need for code.
ECC is a relatively new product, having first arrived as part of Salesforce’s Winter ’20 Release.
Standing up an ECC prediction model is simple and accomplishable entirely through configuration. But given its position towards the left of the maturity curve, we set the expectation with our client that ECC is intended to augment the human aspect of the categorization process rather than replace it entirely.
We see ECC-recommended values as suggestions—they provide a solid starting point for the categorization process rather than acting as its be-all and end-all. As the Einstein suite of products matures, it may become possible to defer to ECC more definitively. But especially for now, we knew it was important to offer a flexible user interface so that users can focus on the work of accurate categorization.
We at Catalyst have built out a custom categorization interface using Salesforce’s Lightning Web Component framework. The component is broken out into two parts: Selected Categories and Potential Categories. As the names suggest, the Selected Categories section holds values that the user (or Einstein) has selected, while the Potential Categories section holds search results returned by a text search.

Take a look at the seamless value search and selection process made possible with a custom interface. Much better than a wall of picklists!
Stay tuned for more material about reference data models from us.
And in the meantime, if you like what you see here, let us know! We’d be happy to sit down and unpack how Catalyst can help make your organization more efficient with a powerful CRM.